# Dataset Description
In this section, a sample refers to "a single image" of welding.
A dataset available in this challenge is described using a Parquet file containing metadata for all samples within the dataset. A Parquet file represents a dataframe. For each sample, the following fields are available:
| Field | Description |
|---|---|
| sample_id | Unique identifier for the sample, following the template "data_X". |
| class | Real state of the welding present in the image; this is the ground truth. Two values are possible: OK or KO. |
| timestamp | Datetime when the photo was taken; this field is not expected to be useful. |
| welding-seams | Name of the welding seam to which the welding belongs. Welding seams are named "c_X". |
| labelling_type | Type of person who annotated the data. Two possible values: "expert" or "operator". |
| resolution | List containing the resolution of the image [width, height]. |
| path | Internal path of the image in the challenge storage. |
| sha256 | A unique hexadecimal key representing the image data, used to detect alteration or corruption in the storage. |
| storage_type | Type of sample storage: "s3" or "filesystem". |
| data-origin | Type of data. This field has two possible values: "real" or "synthetic". The provided datasets contain only real samples. |
| blur_level | Level of blur in the image, measured numerically using OpenCV. The lower this value, the blurrier the image. |
| blur_class | Class of blur deduced from the "blur_level" field. Two classes are considered: "blur" and "clean". The value is set to "blur" when the blur level is below 950. |
| luminosity_level | Percentage of luminosity in the image, measured numerically. |
| external_path | URL of the image. This URL can be used by challengers to directly download the sample from storage. |
Remark : There is no relationship between the integer X in "data_X" value in "sample_id" field and the integer Y in the name of the image "sample_Y.jpeg". in "path" field and "external_path" field.
# Dataset Examples
# Example Mini Dataset
A reduced sample of the dataset "example_mini_dataset" is provided to give an overview of the final dataset for this challenge. This sample contains 2,857 images of welding, split into three different welding seams: c102, c20, and c33.
The metadata file for this dataset can be found here: Example Mini Dataset Metadata (opens new window)
Below is an example of the first nine rows from the metadata file:

The dataset can be downloaded directly as a ZIP file: Download Example Mini Dataset (opens new window)
# Welding Detection Challenge Dataset
The complete dataset provided for this challenge is named "welding-detection-challenge-dataset". It contains 22,753 images of welding, covering three different welding seams: c20, c102, and c33.
The metadata file for this dataset can be found here: Welding Detection Challenge Dataset Metadata (opens new window)
Please note that this complete dataset is the one required for the challenge.
The full dataset can be downloaded as a ZIP file: Download Welding Detection Challenge Dataset (opens new window)
DebiAI is an open-source bias detection and
contextual evaluation tool for AI projects.
We used it to explore the
Welding Detection Challenge Dataset Metadata parquet file:
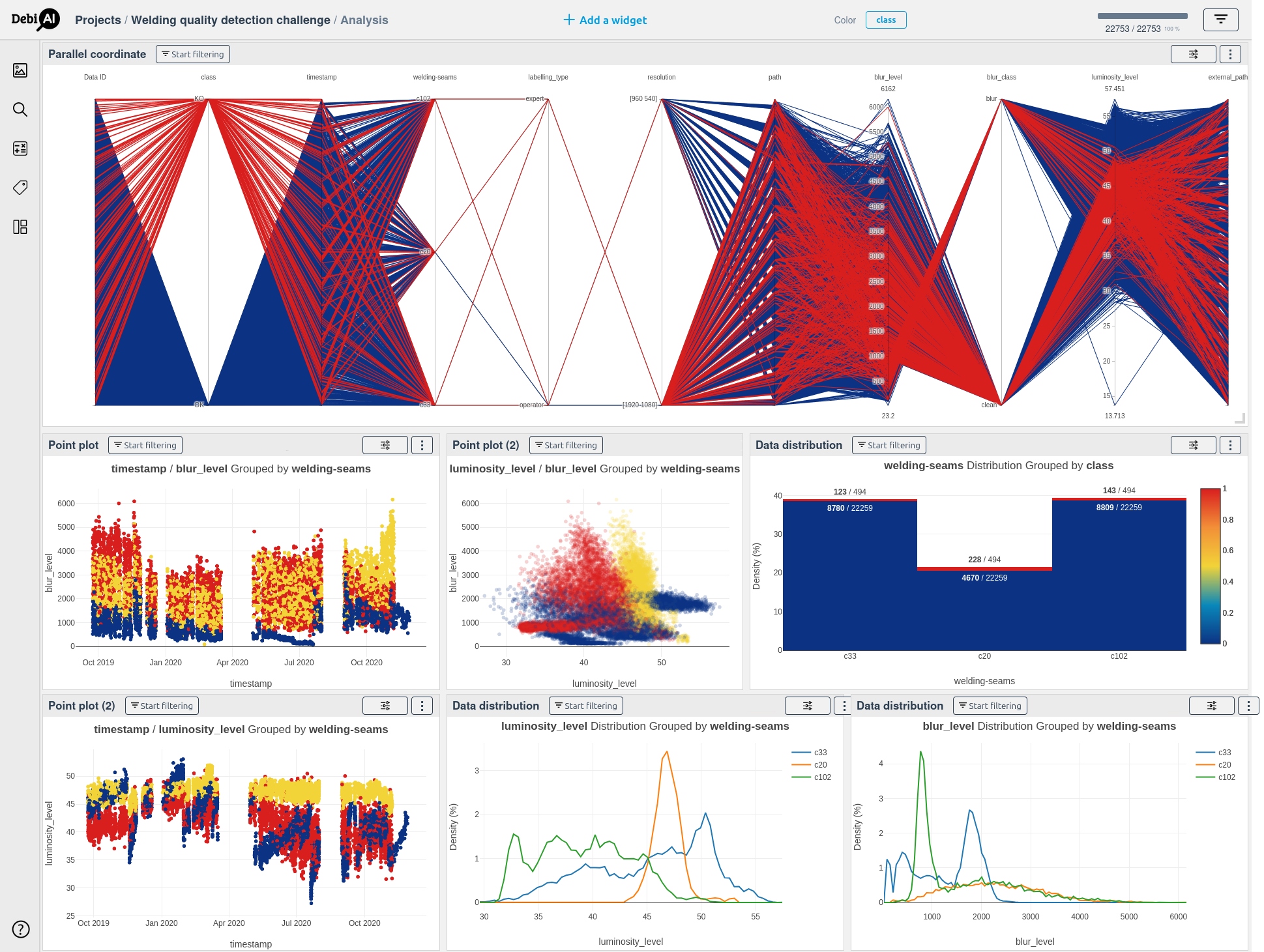
Analyze the challenge dataset on our public DebiAI instance
DebiAI was designed to assist data scientists in exploring datasets like
the one described in this challenge.
How to create your own Challenge Dataset DebiAI project
DebiAI is developed by
![]() And is integrated in
And is integrated in
